DynamoDB Explained

What is DynamoDB?
Amazon DynamoDB is a fully managed NoSQL database service by AWS. It’s designed for high speed, low latency, and automatic scaling, and it’s great for storing large amounts of data — like user profiles, IoT data, game scores, etc.
DynamoDB Architecture Components
Here are the core building blocks:
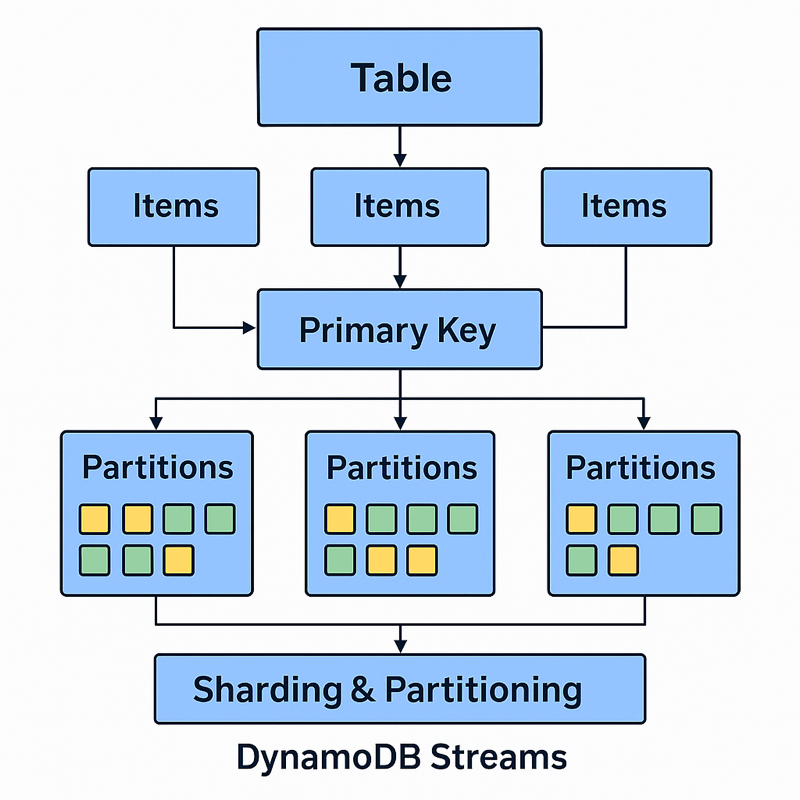
1. Table (Think: Spreadsheet)
Just like a spreadsheet or database table.
Example: Users table with columns like UserId, Name, Email.
2. Items (Think: Rows in the Table)
Each item is a row in the table.
{
"UserId": "123",
"Name": "Alice",
"Email": "alice@example.com"
}Each item must have a primary key (we’ll get to that next).
3. Primary Key (How DynamoDB finds your data)
It can be either:
- Partition Key: Unique ID like UserId
- Partition Key + Sort Key: A combo of two values (e.g., UserId + Timestamp) for sorting items under the same partition
This is how DynamoDB decides where to store and find your item.
4. Partitions (Think: Buckets of data)
DynamoDB stores data in partitions (behind the scenes). The Partition Key is used to decide which partition your item goes into.
If UserId is the partition key, all items with a different UserId go into different “buckets” or partitions.
This is important for scaling and performance.
5. Sharding & Partitioning (Automatic scaling)
- DynamoDB automatically splits your data across multiple partitions based on your workload.
- As your data or traffic increases, AWS silently adds more partitions to spread the load.
- Think of it like spreading your files across multiple filing cabinets when one gets full.
6. Provisioned vs On-Demand Capacity
- Provisioned: You choose how much read/write capacity you want.
- On-Demand: DynamoDB scales automatically — you pay per request.
7. Indexes (Faster searches)
- GSI (Global Secondary Index): Lets you query by fields that are not the primary key.
- LSI (Local Secondary Index): Same partition key, but different sort key.
8. Streams (Event tracking)
DynamoDB Streams lets you track changes (insert/update/delete) to items in real-time — great for triggering Lambda functions.
9. Throttling (When you hit limits)
If your app makes too many requests too fast and goes over your capacity, DynamoDB throttles you — it denies requests temporarily.
That’s why things like evenly distributed partition keys and exponential backoff retries are important.
Visual Analogy
| DynamoDB Concept | Real-world Example |
|---|---|
| Table | A spreadsheet |
| Item | A row |
| Partition Key | Folder label (e.g., UserId) |
| Partition | A drawer that holds folders |
| GSI | An index for quick searching |
| Stream | Security camera recording edits |
| Partitioning | Adding more drawers as you grow |
Example Use Case
You have an app like Instagram:
- Users table: stores profiles with UserId as Partition Key
- Posts table: UserId as Partition Key + Timestamp as Sort Key
- Use GSIs to search posts by Hashtag or Location
- Use Streams to update analytics or send notifications
Architecture Bonus
Think of DynamoDB as a massive digital library that stores books (your data). Now, to find and manage books efficiently, this library is divided into sections (called partitions) — each section holds certain books based on a key.
Partition Key
- It’s like a label on your book (e.g., UserID).
- DynamoDB uses this key to decide which partition (section) your data should go into.
- This is required.
Sort Key (Optional)
- If you have many books (records) under the same partition key, this helps sort them (like organizing by date or name).
- Think of it like shelves inside that section.
What Is a Partition?
- A partition is a physical chunk of storage and compute where your data lives.
- DynamoDB decides which partition your data should go to based on the partition key (like a hashing function).
- Each partition has limits: storage (10 GB) and read/write throughput.
What Is a Shard?
- In DynamoDB, we typically don’t say “shard” (that term is used more in systems like Kafka or Elasticsearch).
- But for context:
- A shard is a general term for a horizontal slice of data in distributed databases.
- In DynamoDB, the closest equivalent to a shard is a partition — they serve the same purpose: distribute data for scale.
Background on difference between Partition and Shard in AWS DynamoDB?
As stated in a Quora: https://qr.ae/pAFibO
A table in DynamoDB represents data as collection of Items.
An Item is similar to a row/record/tuple in an RDBMS.
Each item has a mandatory Partition Key and an optional Sort Key.
The Partition Key for a table has to be unique unless it is also supplemented by an optional Sort Key in which case there could be non-unique partition keys but for each partition key the sort key has to be unique.
What is a Partition?
DynamoDB stores data (Items) of a table in partitions.
A partition is an allocation of storage backed by solid state drives and automatically replicated across multiple Availability Zones within an AWS Region. AWS DynamoDB automatically manages the partition lifecycle under the hood and the user need not worry about it.
Let's see how does DynamoDB writes and reads data pertaining to a table to/from partitions:
Case 1: A Table With A Partition Key
DynamoDB stores and retrieves each item based on its partition key value.
To write an item to the table, DynamoDB uses the value of the partition key as input to an internal hash function. The output value from the hash function determines the partition in which the item will be stored.
To read an item from the table, you must specify the partition key value for the item. DynamoDB uses this value as input to its hash function, yielding the partition in which the item can be found.
This is similar to a MapReduce program with a default Hash Partitioner which partitions the map output based on hashed Keys to a particular partition.
Case 2: A Table With A Partition Key And A Sort Key
DynamoDB calculates the hash value of the partition key in the same way as described in case 1. However, it stores all the items with the same partition key value physically close together, ordered by sort key value.
To write an item to the table, DynamoDB calculates the hash value of the partition key to determine which partition should contain the item. In that partition, several items could have the same partition key value. So DynamoDB stores the item among the others with the same partition key, in ascending order by sort key.
To read an item from the table, you must specify its partition key value and sort key value. DynamoDB calculates the partition key's hash value, yielding the partition in which the item can be found.
What is a Shard?
Before we understand Shard, let's understand what is DynamoDB Stream?
A DynamoDB stream is an ordered flow of information about changes to items in a DynamoDB table. When you enable a stream on a table, DynamoDB captures information about every modification to data items in the table i.e. create, update, or delete to items in the table.
DynamoDB Streams writes a stream record of the items that were modified. A stream record contains information about a data modification to a single item in a DynamoDB table.
In a DynamoDB Stream, the stream records are organized into something called as Shards. Each shard acts as a container for multiple stream records, and contains information required for accessing and iterating through these records.
When you enable a stream on a DynamoDB table, DynamoDB creates at least one shard per partition.
The DynamoDB Streams API can be used to access the stream records within the streams.
Unlike Partitions, Shards are ephemeral i.e. they are created and deleted automatically, as needed.