Elasticsearch Architecture
April 4, 2025 • 3 min read

Elasticsearch is a distributed search and analytics engine. It stores data in a way that makes it easy to search and retrieve very quickly, even if there’s a lot of data.
Architecture
Basic Building Blocks
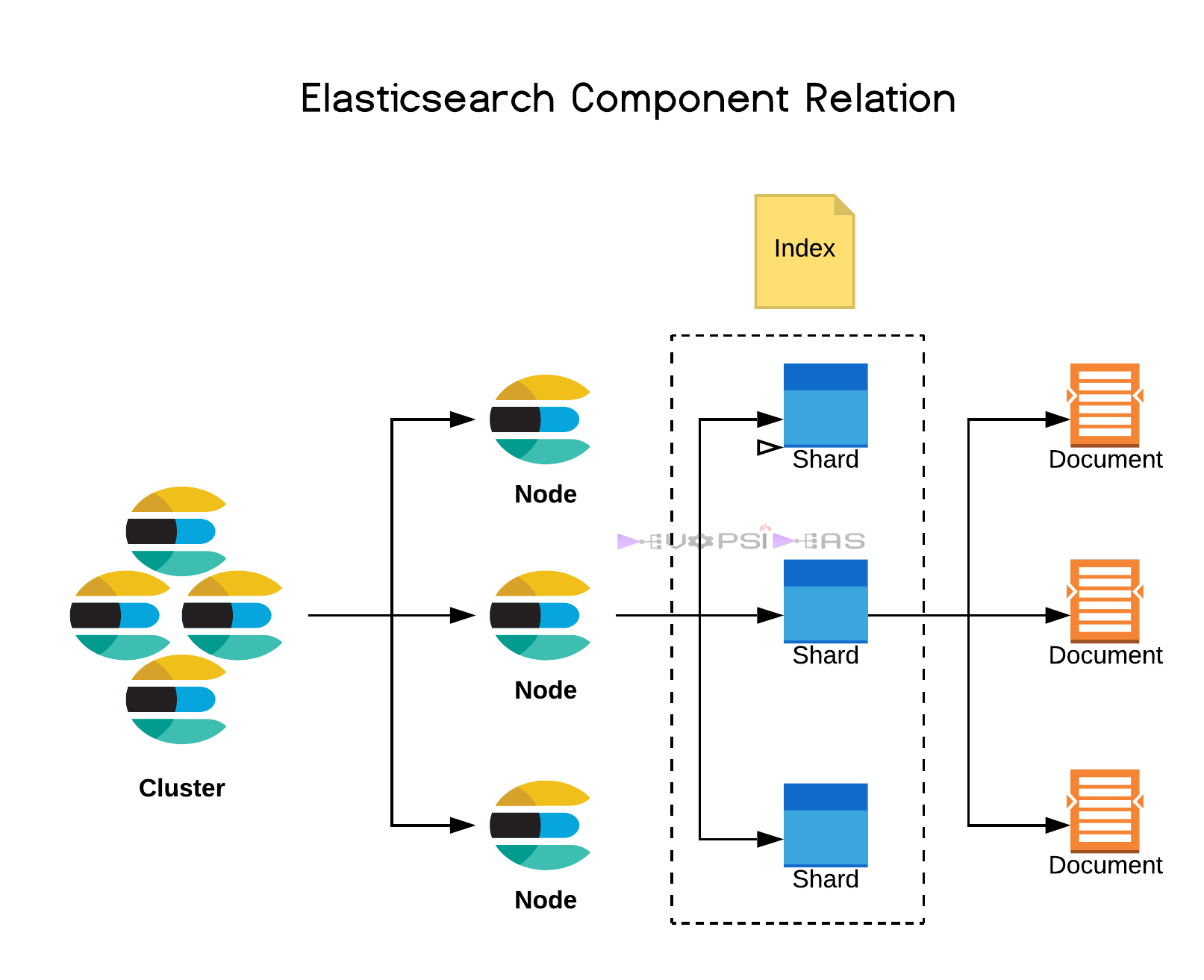
1. Index
Think of this like a database table. It holds related data, like logs, users, products, etc.
2. Document
A single record in Elasticsearch, stored in JSON format. Like one row in a table.
3. Field
A key-value pair inside a document, like user_id: 123.
Shards & Replicas
4. Shards
Each index is broken into pieces called shards.
- A shard is like a mini-index. It holds part of the data.
- Elasticsearch automatically splits and spreads these shards across machines.
- This is how ES scales with large data.
✅ Benefit: Makes data scalable and searchable in parallel.
5. Primary vs Replica Shards
- Primary Shards: Original data.
- Replica Shards: Copies for redundancy and load balancing.
If a machine/node dies, replica shards take over.
Nodes & Instance & Cluster
6. Instance vs Node
- In AWS, instance often refers to the EC2 machine.
- In Elasticsearch, node is the ES process running on an instance.
- One instance can run one or more nodes (though usually one).
7. Node
A single running instance of Elasticsearch (i.e., a single server or container).
- Can be physical or virtual.
- Each node can hold many shards.
8. Cluster
All nodes working together form a cluster. They share the data and work as one big system.
Master vs Data Nodes
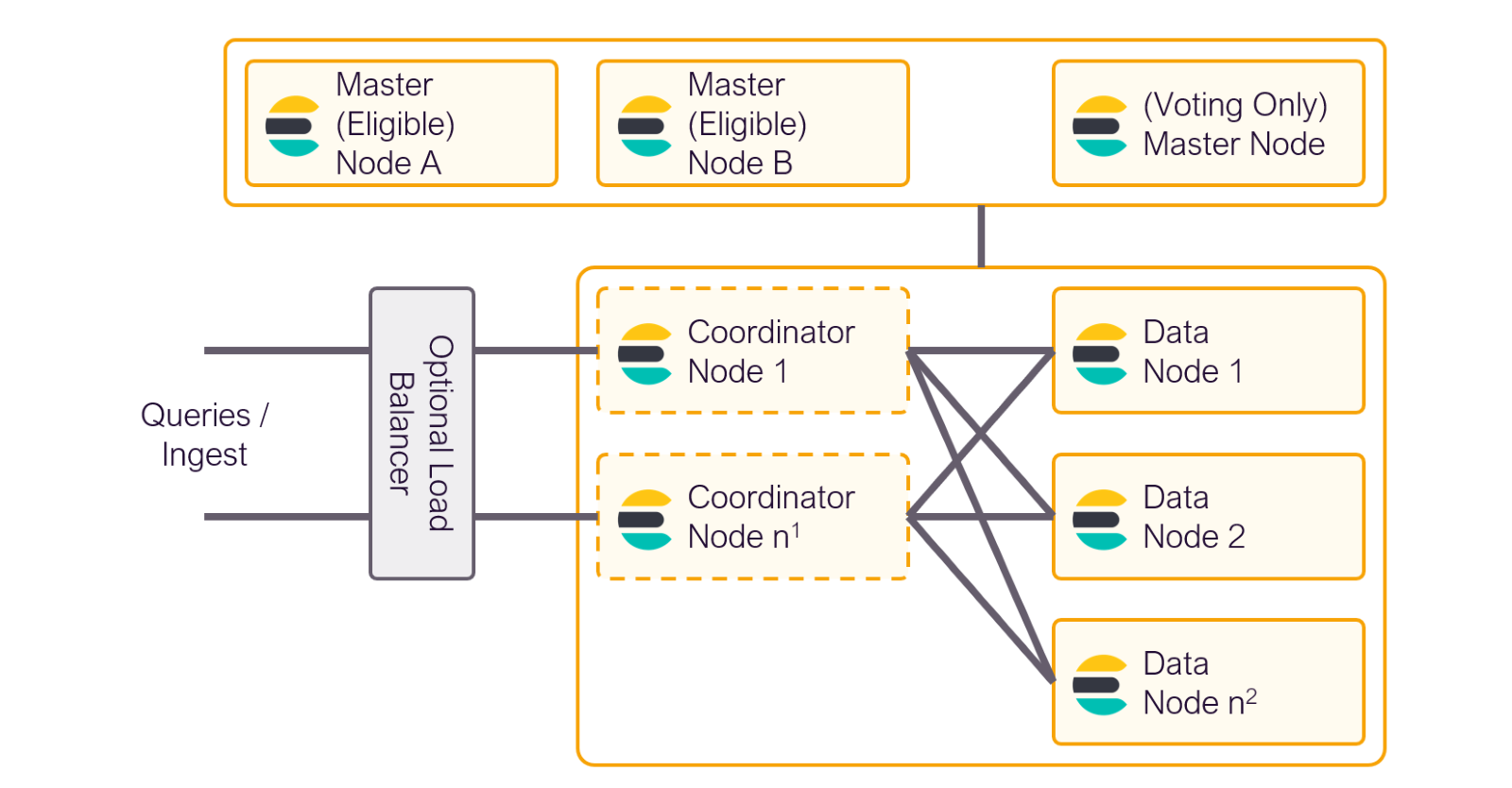
9. Master Node
- Manages the cluster state (which nodes exist, where shards are, etc.).
- Does not store data or handle queries.
- Only one is the active master, others can be backups.
| Term | Description |
|---|---|
| Eligible Master Node | A node eligible to become the master if elected. It participates in the election and cluster coordination. |
| Voting-Only Master Node | A node that can vote in elections, but can never become master itself. |
10. Data Nodes
- Store data and handle search & indexing.
- Most of the load happens here.
- These nodes hold the shards.
Optional:
- Ingest Nodes: Handle preprocessing of data before indexing.
- Coordinating Nodes: Route requests, great for load balancing.
Bonus Examples
- Say You Have Logs Coming In
You store logs in an index called app-logs:
- ES splits app-logs into 5 primary shards.
- You’ve configured 1 replica, so now there are 5 primaries + 5 replicas = 10 shards.
- These shards get spread across multiple nodes.
- The master node keeps track of where everything is.
- When a user searches logs, Elasticsearch talks to all shards in parallel, gathers the results, and returns them.
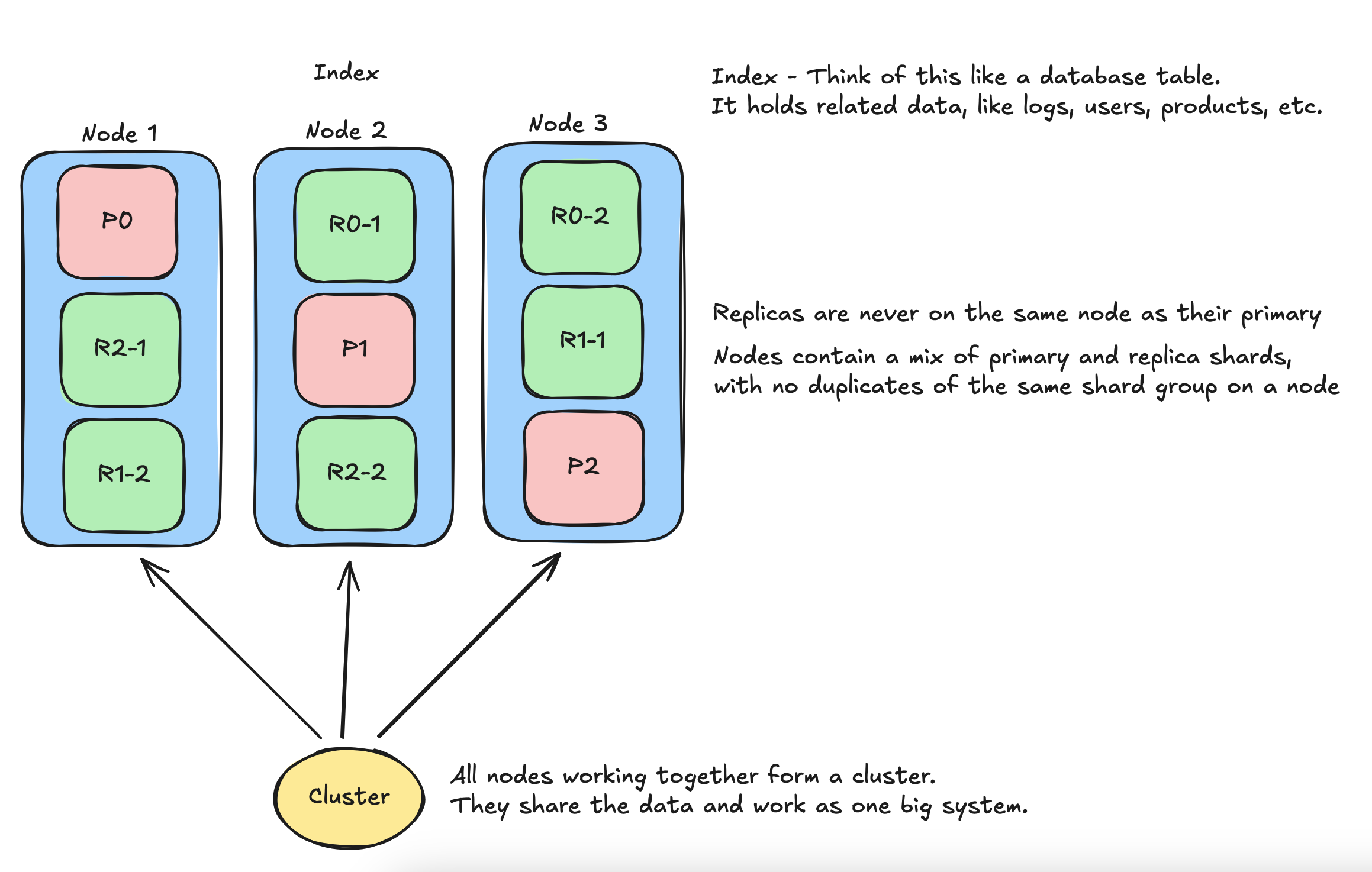
- Say you have:
- 3 Nodes (A, B, C)
- 1 Index called logs with 3 primary shards and 1 replica
Then:
- Elasticsearch will spread:
- Shard 0 primary → Node A
- Shard 0 replica → Node B
- Shard 1 primary → Node B
- Shard 1 replica → Node C
- Shard 2 primary → Node C
- Shard 2 replica → Node A So even if a node goes down, your data is still safe and searchable.
- Elasticsearch will spread:
QnA
- Are data across the shards the same?
No, data across primary shards is not the same.
Each primary shard holds a different portion of your index’s data.
Think of it like this:
Let’s say you’re indexing 9 documents and you have 3 primary shards. The documents might be distributed like this:
Shard Documents Shard 0 (Primary) doc 1, doc 4, doc 7 Shard 1 (Primary) doc 2, doc 5, doc 8 Shard 2 (Primary) doc 3, doc 6, doc 9 So: - Each primary shard has a unique subset of the index’s data
- They do not overlap
- This is called horizontal partitioning
But what about replica shards?
Replicas are exact copies of primary shards. So:
Primary Shard Replica Shard Shard 0 (Primary) Shard 0 (Replica) Shard 1 (Primary) Shard 1 (Replica) Shard 2 (Primary) Shard 2 (Replica) - Used for high availability
- If a primary goes down, its replica can be promoted
Term Holds unique data? Identical copy of another shard? Primary shard ✅ Yes ❌ No Replica shard ❌ No ✅ Yes (copy of a primary)
- How does Elasticsearch decides which shard to write to and which shard to read from?
How Elasticsearch decides which shard to write to:
When you index a document, Elasticsearch needs to decide which primary shard it should go to. It does this using hash-based routing:
shard = hash(_routing or _id) % number_of_primary_shards- By default, it uses the document’s _id field.
- You can override this with a custom _routing value.
- The hash is modded by the number of primary shards → gives the target shard. This means:
- Documents with the same ID or routing go to the same shard
- Evenly distributes documents across shards (usually) How Elasticsearch decides which shard to read from: For searches:
- Elasticsearch queries all primary and replica shards in parallel.
- It can use either the primary or one of its replicas — this gives load balancing and fault tolerance. For document GETs:
- It knows which shard the document is in (based on _id)
- It will route the request to either:
- The primary shard, or
- One of its replicas (again, for load balancing) For updates or deletes:
- These always go to the primary shard
- The change is then replicated to replicas Bonus: This routing logic is handled by the coordinating node, which:
- Receives the request
- Figures out which shard(s) should handle it
- Distributes the work
- Merges the results (for reads)