When to use Kafka

Why Kafka?
Databases have low throughput, which means they struggle with high numbers of read/write operations per second (ops). This can lead to imminent crashes under heavy loads.
For example, consider building a service like Uber. A customer needs to see the real-time location of their rider, and Uber has thousands of riders worldwide. If Uber fetches each rider's location once per second, the resulting massive volume of read and write operations would overwhelm the database, causing it to crash. So, how do we address this issue?
This is where Kafka comes in. Kafka offers very high throughput, allowing us to put and get data efficiently. It is not an alternative to a database but complements it. Kafka's high throughput is balanced by temporary storage, while databases, despite their low throughput, excel at long-term data storage and querying. Combining these technologies helps solve both the high throughput problem and the need for persistent data storage.
Use Case
Consider Uber, where we have 100,000 riders moving at any given moment. Each rider generates data like speed, current location, and telemetry every second, which multiple services need to access.
For example, the following services might use this data:
- Fare calculation service
- Analytics service
- Customer API service
If we were to store all this data directly in a PostgreSQL database at a rate of 100,000 writes per second, we would encounter a throughput problem that could break the database.
Instead, we can feed this data into Kafka. Kafka's high throughput can handle the large volume of data. Here, the client acts as the producer, generating the data. We can then add consumers such as the fare calculation service, analytics service, and customer API service. These services can process the data and perform bulk inserts into the database. By storing data in bulk in single transactions rather than individually, we optimize the database's low throughput capacity.
Kafka Architecture
Key components of Kafka:
-
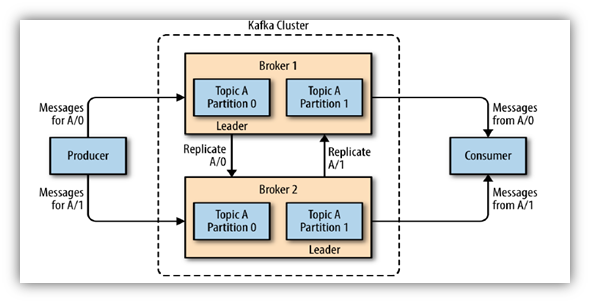
Topics: A Kafka Topic is a collection of messages that belong to a specific category or feed name. Topics organize Kafka's records. In the case of Uber, topics might include rider updates or fare calculations. Consumers subscribe to these topics, and producers feed data into them.
-
Partitions: To manage large amounts of data, each topic is split into one or more partitions. Partitioning logic can be customized, similar to database partitioning. Messages are sent to one partition, which is replicated and has a leader at any given time. Partitions can be distributed across multiple brokers to share the load.
-
Brokers: These are key components of the Kafka cluster that maintain published data. Each broker instance can handle thousands of reads and writes per topic.
-
Producers: Multiple producers can send data to Kafka. The Kafka producer API, including the "KafkaProducer" class, allows producers to connect to Kafka brokers and send messages to a topic asynchronously. Producers determine which partition the messages are sent to.
-
Consumers: Consumers are services that consume Kafka messages. A single consumer can consume messages from all partitions of a topic. If there are multiple consumers, Kafka auto-balances the distribution of partition messages among them. One consumer can consume from multiple partitions, but a partition can only be consumed by a single consumer.
To manage this, we use Consumer Groups. Auto-balancing occurs at the group level. Multiple consumer groups can listen to a single partition, but within each group, only one consumer can consume messages from the partition.